개요
replaylog 관련 timeout 에러가 계속 발생하여, 확인해 본 결과, elasticSearch에 문제가 있었고, 정확히는 wb911 머신에 문제가 발생하였다.
머신에 들어가서 확인해보니, elasticsearch는 작동하고 있었지만, 알 수 없는 ERROR 로그들이 남고있었다. 그 중 하나는 아래 로그이다.
Failed to submit a listener notification task. Event loop shut down? java.util.concurrent.RejectedExecutionException: event executor terminated elastic
일단 NSight를 확인해보니, 머신이 터지기 직전이여서, 재부팅을 부탁드렸다(다행히도 머신이 문제가 발생하자마자 메신저 주심).

발생 원인
Failed to submit a listener notification task. Event loop shut down? java.util.concurrent.RejectedExecutionException: event executor terminated elastic해당 로그에 대해 구글링 해보면 , 클러스터에서 사용중인 노드의 리소스 부족(샤드 개수) 관련한 이야기가 많다.
현재 클러스에서 사용중인 샤드 개수는 1636개인데, 이는 인덱스당 노드를 잡을 때 40GB 당 1개로 설정하였다.(Elastic 공식문서 가이드)
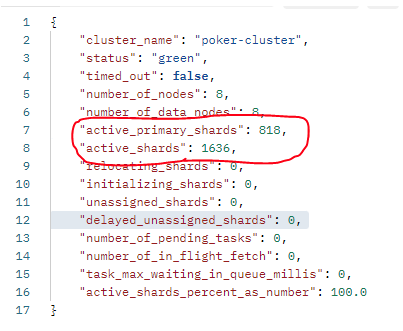
근데 문제는 Elastic 공식문서 가이드에 따르면, 힙 메모리 1GB 당 샤드 개수를 최대 20개로 제한 해야한다.(7.10.2 버전 기준)
노드 당 힙 메모리 8GB을 사용 중이고, 8개의 노드(머신)을 사용중이니, 최대 64 * 20 = 1280가 되어야 하는데, 1636개를 사용 중이여서, 문제가 발생할 여지가 있다.
해결 방법
공식 가이드에 따르면, 해결방법은 아래와 같다.
- ILM을 설정하여 인덱스를 shrink 하거나, delete
- 시계열 인덱스을 사용 중 이라면 롤 오버 단위를 늘리는 방법(1d -> 1M로)
- 머신을 추가하는 방법
- 최신버전으로 업그레이드 하는 방법 (최신 버전은 1GB당 3000개)
이 중 새로운 인덱스를 생성하는데 시간 단위를 늘리는 방법이 가장 좋은 방법인 것 같다. 특히 ccu, classic, client 로그들은 하루에 2GB 미만이므로, 샤드 1개를 활용하는 것도 과하다 볼 수 있다.
특히 동접지표에 사용되는 CCU는 2022년 7월 부터 매일 3mb 크기의 인덱스를 생성중이다. CCU 같은 경우는 인덱스를 merge하는 과정도 필요할 것 같다.
해당 지표들은 매일 새로운 인덱스를 롤링하는 것이 아닌, 1달에 한번 롤링된다
로그스태시 설정 변경
output에서 {+YYYY.MM.dd} -> {+YYYY.MM} 으로 변경한다.
변경 전
output {
if([message] =~ /(CCU)/) {
elasticsearch {
hosts => ["호스트 IP"]
user => "아이디"
password => "비밀번호"
index => "인덱스-%{+YYYY.MM.dd}"
}
} else if([message] =~ /(AbuserTracker)/) {
elasticsearch {
hosts => ["호스트 IP"]
user => "아이디"
password => "비밀번호"
index => "인덱스-%{+YYYY.MM.dd}"
}
변경 후
output {
if([message] =~ /(CCU)/) {
elasticsearch {
hosts => ["호스트 IP"]
user => "아이디"
password => "비밀번호"
index => "인덱스-%{+YYYY.MM}"
}
} else if([message] =~ /(AbuserTracker)/) {
elasticsearch {
hosts => ["호스트 IP"]
user => "아이디"
password => "비밀번호"
index => "인덱스-%{+YYYY.MM}"
}
중략...ccu , abuser-tracker 인덱스 삭제
ccu 와 abuser-tracker 인덱스는 ILM 설정없이 매일 남기고 있었다.
그러다 보니, 100MB도 안되는 용량인데 매일 남기다보니, 불필요한 샤드 사용이 있었다.
삭제 이후 샤드 상태는 아래와 같다.

active 샤드가 950개로 안정권에 들었다.
'개발자로서 살아남기 > ELK Stack 적용하기' 카테고리의 다른 글
| ElasticSearch 클러스터 노드 용량 불균형 문제 해결 (0) | 2025.05.23 |
|---|---|
| ELK - 엘라스틱 서치에 L4 붙일 때 문제점 (0) | 2023.10.04 |
| ELK - primary shard is not active Timeout 에러 (0) | 2023.06.22 |
| ELK - Retrying individual bulk actions that failed or were rejected by the previous bulk request. retrying failed action with response code: 403 에러 발생 (0) | 2023.06.14 |
| ELK 인덱스 생명 주기(ILM) 설정하기 (0) | 2023.05.16 |